当我们聊消息队列,我们在聊什么
一、What is messaging
request-response模式
本地系统(client)与通过远程系统(server)暴露的通信终端进行同步通讯。在形式上无论是远程系统调用,还是web service调用,或者是远程资源的消费,这些在本质上都是一个模型,只是表现形式不同:本地系统向远程系统发送消息,本地系统同步等待远程系统返回应答,系统之间通过点对点的方式通讯。

one way style模型
在one way style方式中,系统之间通过传递消息的方式异步交互,所谓异步也就是系统A在发送完消息之后不需要同步等待系统B的应答。

loosely coupled模型
在one way style方式中,系统之间通过传递消息的方式异步交互,所谓异步也就是系统A在发送完消息之后不需要同步等待系统B的应答。

消息传递模型
在实时流式架构中,消息传递能够分为两类:队列(Queue)和流(Stream)。
队列(Queue)模型
A *queue* is a simple FIFO mechanism allowing you to add items to the back of the queue or take from the front.
- 消息只能被消费一次
- 消息不能被回溯
- 通常和生产消费者模式一起
流式(Stream)模型
A *stream* is not really a data structure as such (conceptually), but is a sequence of digitally encoded coherent signals (packets of data or data packets) used to transmit or receive information”. So basically a sequence of data.
- Streams always have a source
- stream processing
- With Pub/Sub pattern
In stream processing, you apply complex operations on multiple input streams and multiple records (ie, messages) at the same time (like aggregations and joins).
Queue & Stream
当前的分布式消息中间件几乎很多都不单纯是消息队列,还提供流式处理的能力,例如kafka,不仅可以发布订阅stream,还可以存储记录,甚至可以做一些简单的streamprocessing。而Apache pulsar直接在消费模型上面,讲queue和stream统一起来都实现了。queue和stream虽然有一些不同,但是界限变得越来越模糊了。
二、Why message queue
消息队列的作用:
异步
解耦
削峰
disadvantage:
maintain message queue
Consume same message twice
Lose message
Inconsistency
Availability
三、Reliability
producer→Broker→Consumer 链路可靠
producer:幂等重试
Broker:消息可靠存储
消息持久化
多副本
故障转移
Consumer: Ack机制
业务幂等
Ack机制
四、 Availabilty
Broker无状态
Message Store多副本
故障自动转移
五、Performance
顺序写入
partition
批量
I/O 分离
cache
broker cache
page cache
Log cache
zero copy
数据压缩
良好设计的消息队列,系统的吞吐取决于网卡,如何设计出低延迟的消息系统也很关键;
Low latency:
tailing read
cache
并行读
write
- WAL
六、(How) Message queue Design
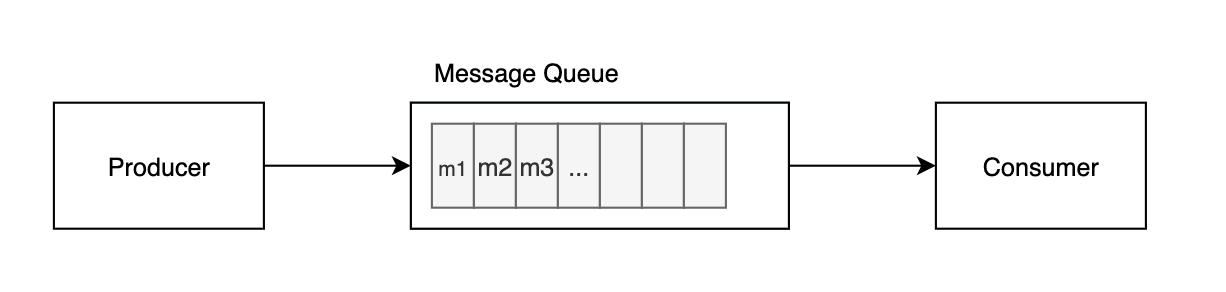
Message Queue
Queue implements load balancer semantics. A single message will be received by exactly one consumer.
点对点(point-to-point)
disadvantage:
point-to-point(1→1),多个消费者需要多个message queue
下游增加消费者,需要上游添加message queue
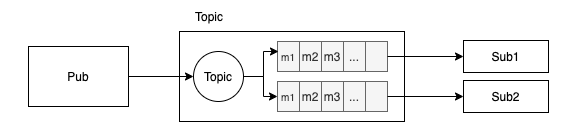
Topic
Topic implements publish and subscribe semantics
publisher-subscriber model
publish-and-subcribe(1→many)
镜像queue
- 不同的subscription使用不同的镜像queue,存储不同
disadvantage:
- 数据冗余,有一定存储和性能浪费
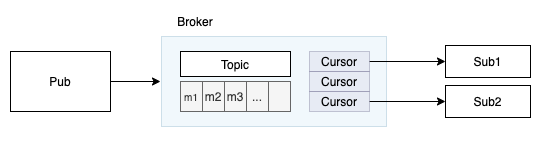
Cursor
同一份数据存储
subscription维护各自的Cursor(消费游标)
Partition Topic
单个Topic存在的问题:
- topic过大,broker & store 存在瓶颈
解决方案:
拆分成多个partition
partition是逻辑分片,对业务透明
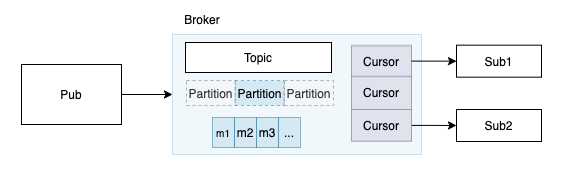
计算和存储分离
Broker状态
Topic Store水平扩展
【注】多一层会额外引入性能损耗&系统复杂性
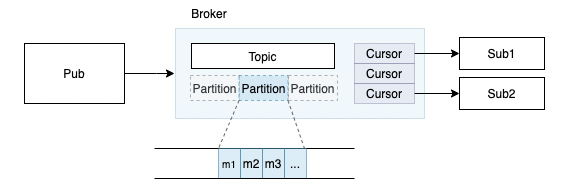
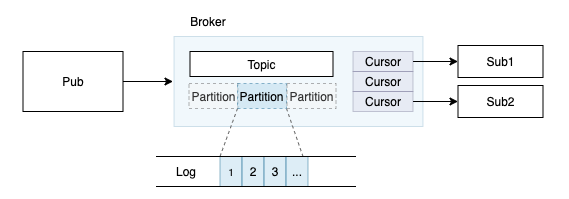
Topic Store : Distribute Log
Message queue可以看作是一组有序的数据流(Stream);
日志是一种简单的抽象,只能追加,按时间有序的序列;
日志是持久化的数据流;
Topic Store核心是日志,分布式消息队列的底层存储是Distribute Log System;

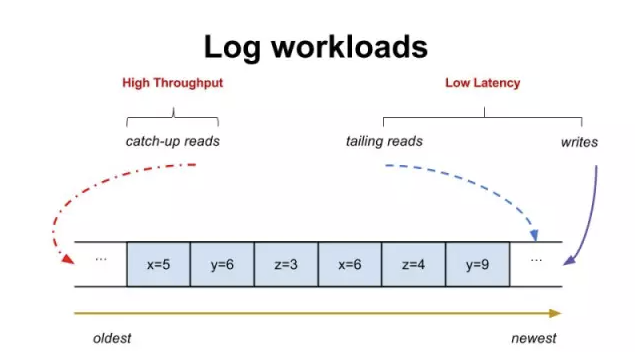
Log workloads: low latency,High throughput
日志系统的核心负载可以归为三类:writes,tailing reads,catch-up reads
Writes 和 tailing reads 在意的是延时 (latency),因为它关系到一个消息能多快地从被写入到被读到。
而 catch-up reads 在意的则是高吞吐量,因为它关系到是否能追赶到日志的尾部。
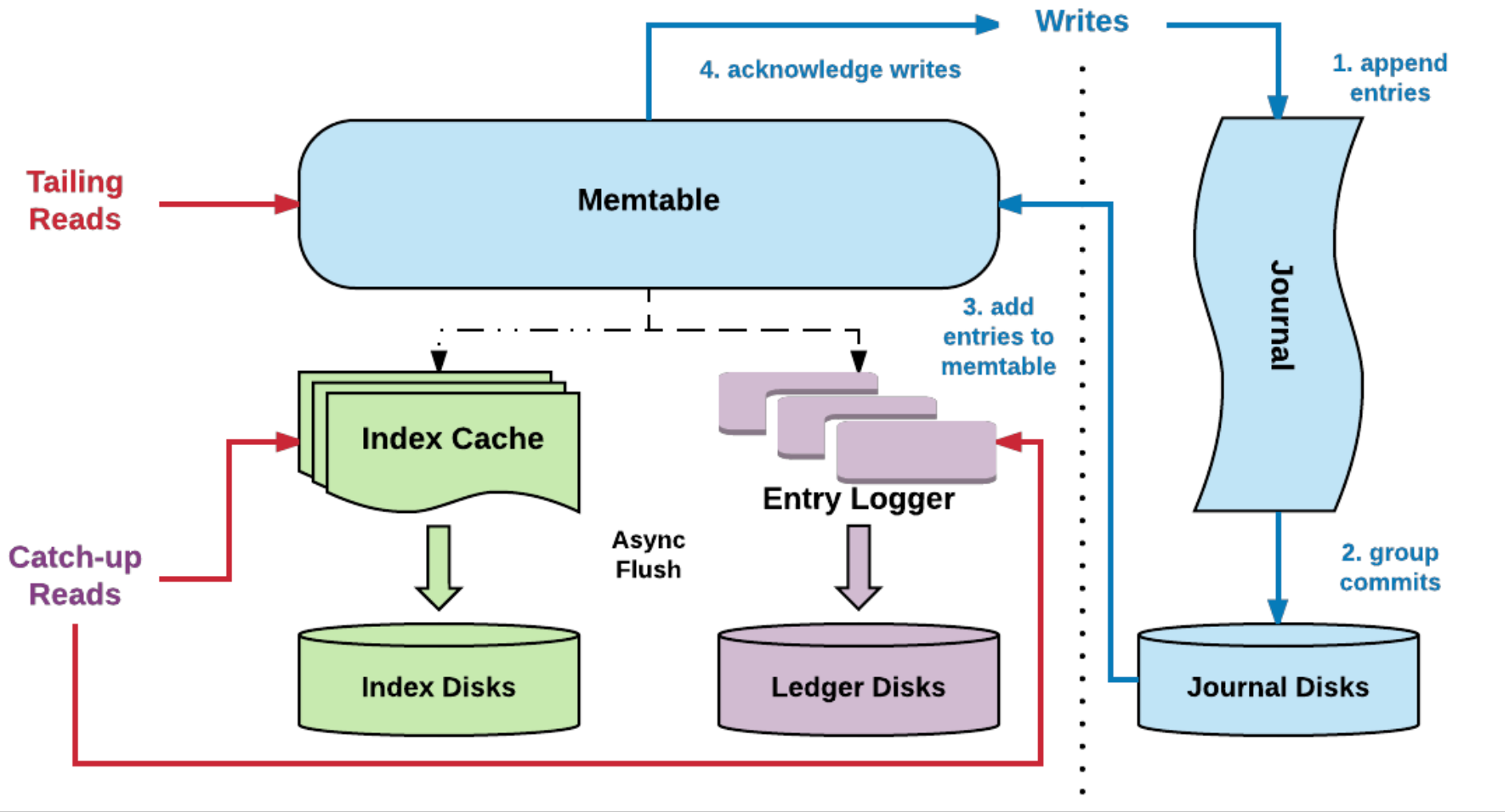
tailing reads: log cache & broker cache &page cache
- catch-up reads可能会造成cache污染
writes: append only
topic维度的顺序写
Write Ahead Log
catch-up reads
- 避免污染cache
工程投影:分布式日志系统Bookeeper
高级功能
- 顺序保证
- 单个partition有序
- 延迟队列
- 事务消息
- 跨地域复制
- 多租户
- 租户隔离
- 租户调整有挑战
- 消息语义保证
- at least once
- at most once
- extractly once